Evaluate OCR Data
Scribe OCR can be used to evaluate the accuracy of OCR data by comparing against ground truth data. This can be used to benchmark different OCR programs or configurations.
1. Create Ground Truth Data
Ground truth data is simply data in any supported OCR data format that is assumed to be 100% accurate. Ground truth data can be created using Scribe OCR by simply using the program as usual–recognizing text and correcting any errors–and then downloading the corrected data as .hocr.
2. Compare Raw OCR Data with Ground Truth Data
To compare raw OCR data with ground truth data, perform the following steps.
- Import the raw OCR data and image files as you would normally.
- If benchmarking Scribe OCR’s internal engine, upload the image/PDF file(s) and run recognition.
- Enable the optional “Evaluate Accuracy” feature.
- Select
Info->Optional Features->Evaluate Accuracy.
- Select
- Upload the ground truth data, and mark it as ground truth.
- Select
Evaluate->Upload OCR Data->Choose Files, and select the ground truth data. - Set a name for the dataset, and then click
Upload. - Set the ground truth as active by selecting it from the
Active OCR Datadropdown menu. - Click
Set Ground Truthto mark the active OCR data as the ground truth.
- Select
3. Review the Differences
To review raw OCR data, set the dataset being compared as “active” using the Active OCR Data dropdown menu in the Evaluate tab. Page-level and document-level accuracy statistics will be calculated and displayed on the Evaluate tab, as seen below.
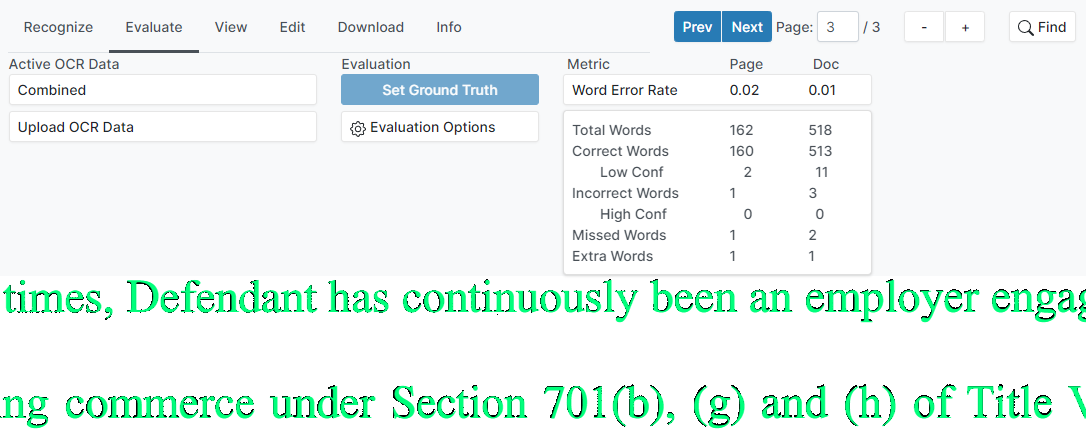
Individual incorrect words can be easily identified by changing the display mode. By selecting View -> Display Mode -> Evaluate, words that match the ground truth data will be displayed in green, while words that do not match the ground truth data are displayed in red.