Overview
Scribe OCR supports visual debugging of various recognition steps using features adapted from the Java ScrollView program in Tesseract. The utility of these visualizations, as well as how to produce and view them, is described below.
What do visualizations show?
Debugging visualizations provide a view “under the hood” during the first several steps in the recognition process: image processing, layout analysis, and word/noise detection. They show the text blocks, lines, words, etc. as they exist at various steps. As a result, these visualizations are useful for answering questions such as “why is this word missing from the output” or “why are lines from different columns being combined,” and are not useful for questions such as “why is this word being misread as a different word.”
Who are visualizations for?
Debugging visualizations are generally only useful to developers. There is no way for non-developer users to influence most of the steps the visualizations show, so outside of satisfying curiosity, this information is unlikely to assist non-developer users with improving accuracy. Additionally, interpreting the visualizations may require referring to source code. Neither Scribe OCR nor Tesseract maintains documentation on the meaning of visualizations.
Enabling Debugging Visualizations
To enable visualizations, using a fresh session, select Info -> Debugging Visualizations -> Enable ScrollView. This must be done before running recognition.
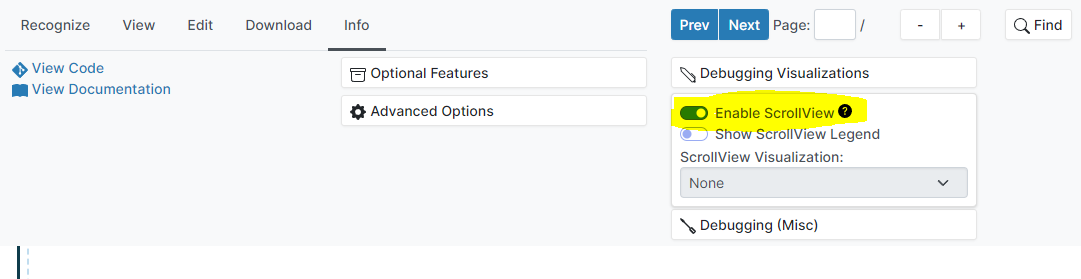
Next, upload your document and run recognition. Documents should be of a reasonable size as generating visualizations consumes a significant amount of memory for every included page. Attempting to generate visualizations for a large document with 50+ pages will likely crash the program.
After recognition is complete, visualizations can be viewed by selecting a visualization from the ScrollView Visualization drop-down menu.
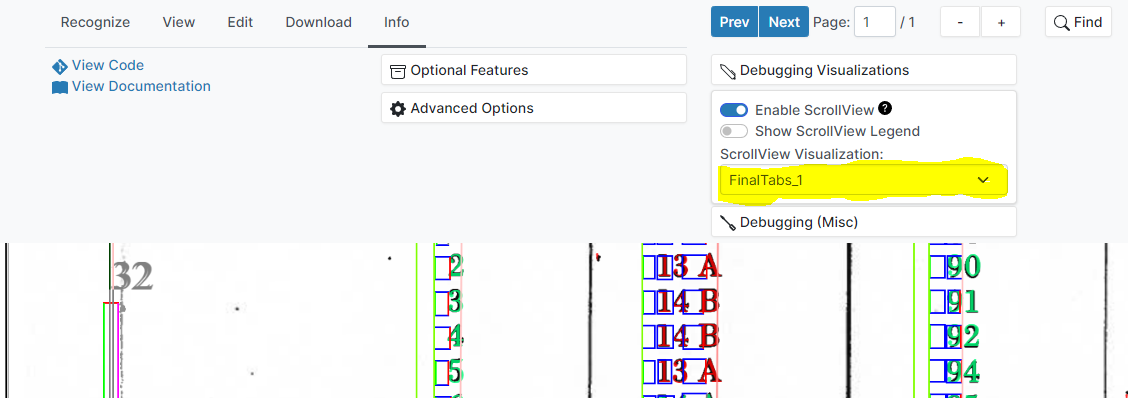
For some visualizations, build-in legends can be displayed to show what values various colors correspond to. These legends can be displayed by selecting the Show ScrollView Legend option.
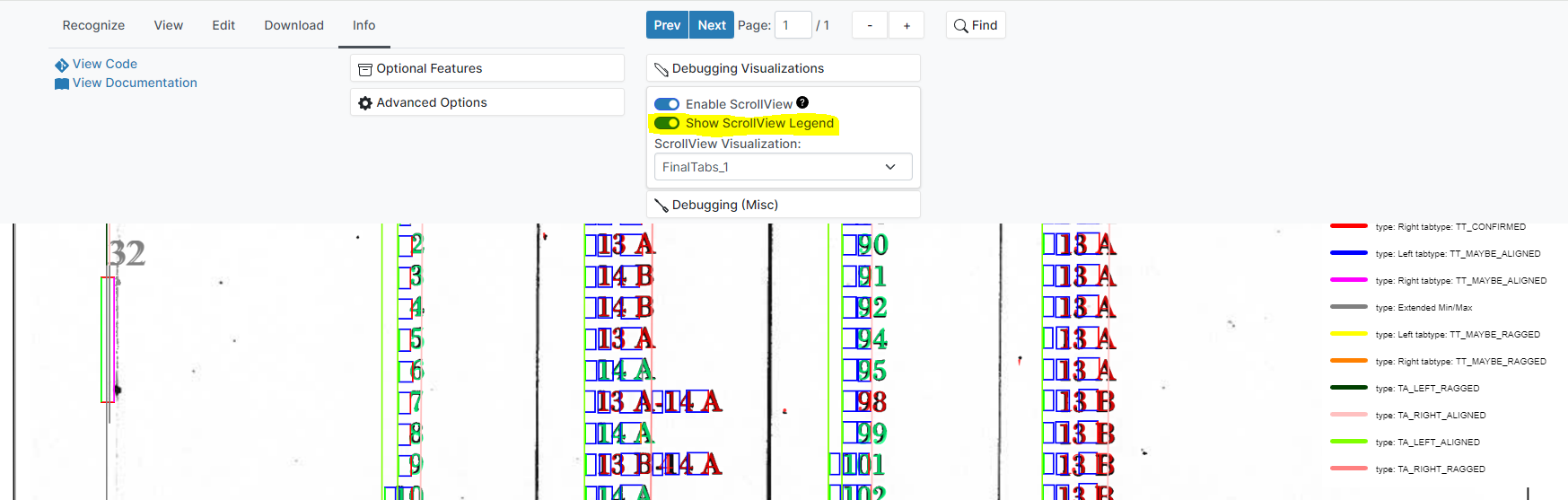
Legends list the mapping between colors and values, however do not explain what various terms mean. Therefore, even when legends exist, referring to Tesseract source code may still be necessary to interpret visualizations.
FAQ
How do I interpret [x] visualization?
Debugging visualizations are primarily a developer resource, and we do not maintain documentation explaining how to interpret visualizations. If the meaning of a visualization is unclear, users should consult the Tesseract source code. If you have a quick question about a specific visualization you may open a Git Discussion asking.
How do these compare with the visualizations produced by the Tesseract ScrollView program?
The vast majority of debugging visualizations produced by Scribe OCR are inherited from the Tesseract ScrollView program. The visualization name, meaning, and color-coding are generally the same.
In some cases, additional visualizations were added to provide better coverage of important steps that previously lacked visualizations. For example, additional visualizations were added to show column detection. In other cases, visualizations produced by Tesseract are omitted to avoid cluttering the interface and avoiding excessive memory usage.
Why do visualizations sometimes not align with the background image?
Tesseract makes transformations during the recognition process to attempt to deskew the input. Visualizations produced using transformed coordinates will not align perfectly with the source image. However, these visualizations should generally still be readable.
Can this debug interface be used with Tesseract.js or Tesseract CLI/API?
At present, only the Scribe OCR fork of Tesseract is compatible with the JavaScript renderer/viewer. The only way to produce similar versions using the main Tesseract program is using the Java ScrollView program. It is possible that Tesseract (and Tesseract.js) could be updated to generate debugging files that can be used with a web viewer in the future. If this is something you would use, thumbs-up this git issue to indicate interest.